Longest Substring Without Repeating Characters
https://leetcode.com/problems/longest-substring-without-repeating-characters/
给定一个字符串,找出最长不重复子串的长度。
Solution 1
第一个解决方案依然采取最直观的方式,就是做两层遍历,从前往后逐个字符比较。
class Solution {
public:
int lengthOfLongestSubstring(string s) {
int length = 0;
for (int i = 0; i < s.length(); ++i) {
int sub_length = 1;
string sub_str = s.substr(i, sub_length);
for (int j = i + 1; j < s.length(); ++j) {
if (sub_str.find(s[j]) != string::npos) {
break;
}
sub_str += s[j];
sub_length++;
}
if (sub_length > length) {
length = sub_length;
}
}
return length;
}
};
提交代码,Accepted,但是 Runtime 164ms,太惨了…
初步分析是 sub_str.find 花费了相当多的时间。
Solution 2
既然怀疑是 find 花费了较长时间,那么在这个方案里,我们就使用 Hash Table 来去掉 find 的过程。
class Solution {
public:
int visited[256];
int lengthOfLongestSubstring(string s) {
int length = 0;
for (int i = 0; i < s.length(); ++i) {
int sub_length = 1;
memset(visited, 0, 256 * sizeof(int));
visited[s[i]] = 1;
for (int j = i + 1; j < s.length(); ++j) {
if (visited[s[j]] != 0) {
break;
}
visited[s[j]] = 1;
sub_length++;
}
if (sub_length > length) {
length = sub_length;
}
}
return length;
}
};
这里定义一个 visited 数组来标记访问过的字符,这样在遍历的时候我们能直接通过这个数组来查找到当前访问的字符是否已经在前面出现过。
这一次提交后,运行时间减少到了 60ms,比上面少了足足 104ms,不过只击败了 33.96% 的 C++ 提交代码。
Solution 3
上面的两个解决方案的算法复杂度都是 O(n^2),这一次我们试着能不能把复杂度降低为 O(n),只通过一次遍历就实现这个算法。
这里我们分析一个比较极端的字符串例子abcdeFghFijk。首先按照上面两个方案遍历这个字符串,当第一次循环的时候,我们的子串是从 a 开始,然后直到碰到了第二个 F 结束。然后我们依次从 b、c、d、e、F 开始子串,最终都是碰到第二个 F 结束。我们会发现不管第一个 F 之前有多少不字符,最终这个子串都会到第二个 F 处结束,而且这些子串肯定比我们第一次循环的子串短。也就是说我们后面做的这几次循环其实都是多余的,我们第二次循环只要从第一个 F 后面的 g 开始就行了。
class Solution {
public:
int visited[256];
int lengthOfLongestSubstring(string s) {
int length = 0;
int start_index = 0;
memset(visited, -1, 256 * sizeof(int));
int i = 0;
int sub_len = 0;
for (i = 0; i < s.length(); ++i) {
if (visited[s[i]] != -1 && visited[s[i]] >= start_index) {
if (sub_len > length) {
length = sub_len;
}
start_index = visited[s[i]] + 1;
sub_len = i - start_index + 1;
} else {
sub_len++;
}
visited[s[i]] = i;
}
if (sub_len > length) {
length = sub_len;
}
return length;
}
};
这一次,我们同样定义了 visited 数组,另外还定义了一个 start_index 来保存子串的开始位置。与上面同的是这一次 visited 中保存的是字符出现的下标位置,而不是上一个方案中只是简单的表示出现与否的 0 或 1。 然后我们在一次循环中,在不断向前遍历的同时,也在不断地调整子串的开始位置 start_index。这样就实现了算法复杂度为 O(n) 的解决方案。
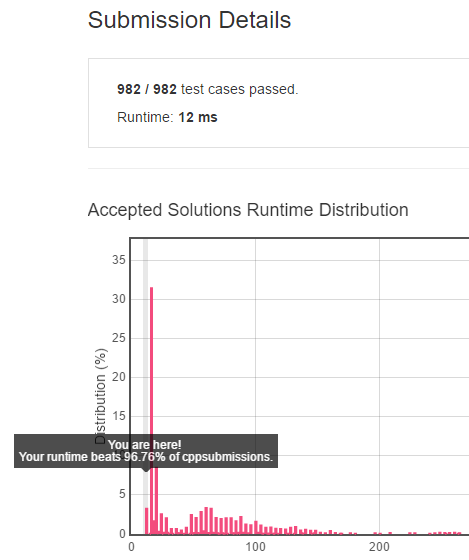
提交上去,这次运行时间只有 12ms,超过了 96.76% 的 C++ 提交代码!